
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- FCM
- enumSet
- 테크쇼
- 일상
- 2024회고
- Java
- MySQL
- Server
- 공룡책
- modelmapper
- Coputer Science
- 직장인 회고
- Spring
- OS
- 2025 계획
- Junit 5
- softeer
- 인프콘2023
- Test code
- mapstruct
- Test Doulbe
- Service 계층 테스트
- 소프티어
- db
- 자바
- Test
- parallelconsumer
- JPA
- proxyFactory
- backend
- Today
- Total
공부내용공유
Redis 알아보기 (feat: redis는 single thread?) 본문
서론
최근 프로젝트를 진행하면서 풀어야할 요구사항이 있었는데 여러가지 방법이 있었지만 redis를 사용하면 어떨까 싶은 생각이 들었었다, 다만 redis를 사용해야하는 이유에 대해서는 단순히 in-memory라 빨라서, 여러 서버에서 접근이 가능해서 등등 추상적인 답변만 떠오르고 정확히 어떻게 동작하고 어떤 기능을 지원하는지 설명할 수 없었다.
이전에 들었던 redis 관련 세션 복습겸, 내용 정리를 한번 더 하고자 해당 글을 작성하였고 이번 글에서는 redis가 일반 db(disk를 주로 사용하는)보다 왜 빠른지에 대한 내용을 다룰 것이다.
본론
해당 글은 목차는
- Redis 간단하게 알아보기
- Redis는 싱글 스레드?
- Redis는 왜 빠를까?
로 구성될 예정이다.
Redis 간단하게 알아보기
redis는 key / value 형태로 값을 저장하는 NoSQL DB의 한 종류이다.
MySQL 이나 MongoDB와 같은 전통적인(?) 데이터베이스들은 주로 데이터를 secondary storage에 저장을 하는 반면 redis의 경우에는 주로 RAM 데이터를 저장하고 사용한다.
RAM에 접근하는데 걸리는 시간이 100ns인 반면 SSD에 접근하는 시간이 100ms인걸 보면 단순 조회에 있어서 RAM에서 읽어올 때, secondary에서 읽어올 때의 차이는 1000배의 차이가 있음을 알 수 있다.
redis는 이렇게 RAM 데이터를 저장하고 조회하게 해주는데 string, hash, set, sorted set, streams과 같은 다양한 자료구조를 제공해준다.
이러한 특성을 기반으로
- 실시간 채팅
- session storage
- streaming
등과 같은 곳에 사용이 가능하다.
Redis is an open source data structure server.
It belongs to the class of NoSQL databases known as key/value stores. Keys are unique identifiers, whose value can be one of the data types that Redis supports.
These data types range from simple Strings, to Linked Lists, Sets and even Streams.
Each data type has its own set of behaviours and commands associated with it.
Redis는 싱글 스레드?
그리고 redis에 관해 검색을 해보면 항상 single thread라는 키워드가 따라다닌다, 또 가끔 보면 엄밀히 말하면 single thread가 아니다라는 글도 보인다. 어떤 의견이 맞는걸까?
많은 어플리케이션에서 멀티 스레딩을 활용하여 어플리케이션의 성능을 높였다, 다만 멀티 스레딩을 적용하기 위해 공유 자원에 대해 락을 걸어주고 synchronization을 해줘야하는 복잡성이 추가가 된다.
redis는 분명 싱글 스레드 방식을 사용하여 위와 같은 복잡성을 배제하였다. 그렇다면 redis는 어떻게 수많은 서버에서 들어오는 요청을 처리할 수 있을까? (get / set의 경우 흔히들 10만 tps까지 감당할 수 있다고 한다.)
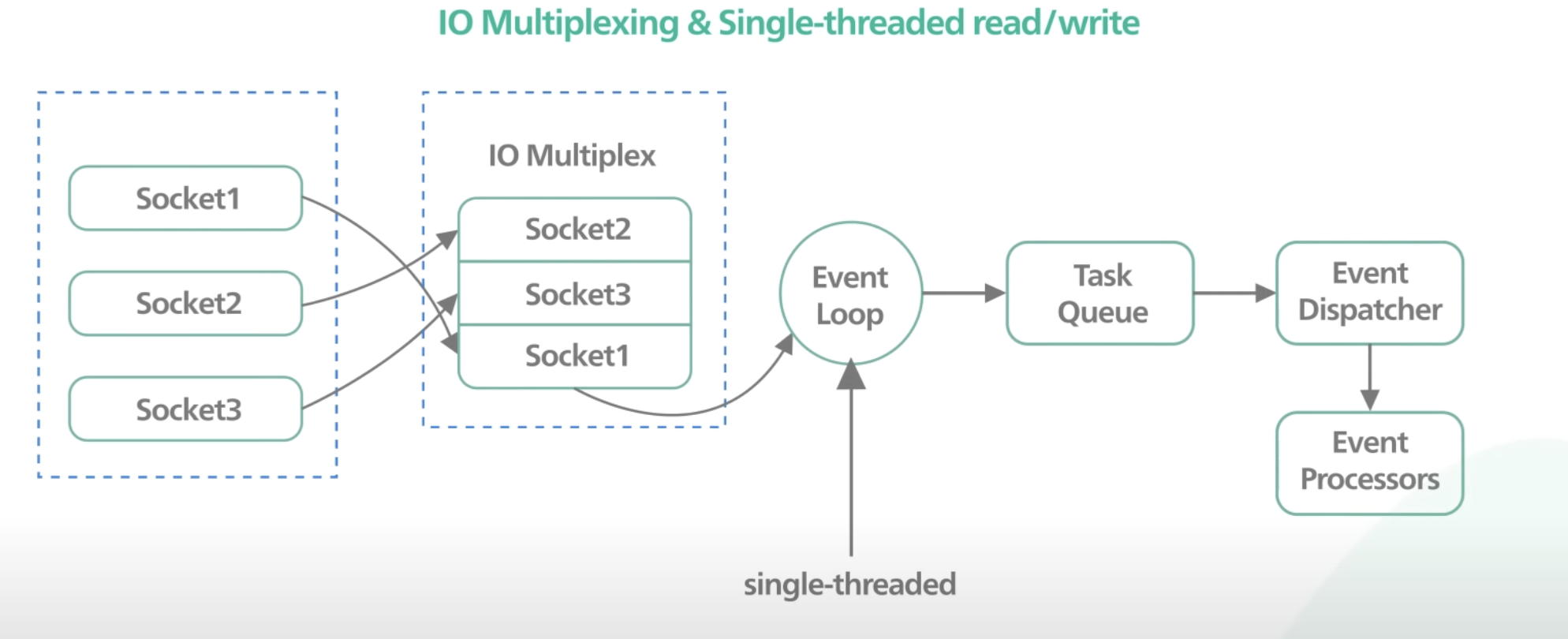
해당 사진에서 볼 수 있듯이 multiplexing 방식으로 클라이언트의 요청을 받아 event loop에서 싱글 스레드로 처리를 한다. (이전에 select, poll 과 같은 시스템 콜을 사용하였고 현재는 좀 더 효율적인 Epoll, variant of I/O multiplexing 방식을 사용한다.)
사용자의 요청을 받을 때와 해당 요청에 대해 메모리에 I/O 작업을 할 때는 멀티 스레드 방식으로 처리하고 각 요청들을 queue에 넣고 처리하는 것은 싱글 스레드로 동작하는 것이다.
이를 통해 각 수행되는 명령들의 원자성을 보장할 수 있고 컨텍스트 스위칭 없이 빠른 작업이 가능하며 redis 자체도 좀 더 간결한 디자인을 가져갈 수 있다.
다만 이렇게 설계가 된것은 CPU bounded task가 적을 거라는 가정하에 만들어졌기에 cpu 작업을 길게 필요로하는 요청의 경우 병목 현상을 발생시킬 수 있다.
여담으로 redis를 실행시키면 스레드가 여러개가 떠있는 것을 확인할 수 있는데 이는 redis의 event loop을 처리하는 스레드가 아니라 디스크에 flush하거나 OS 작업을 위한 스레드이다.
Redis는 왜 빠를까?
찾아봤을 때 정말 다양한 이유들이 많았는데 몇 가지를 리스트업 해보면
- disk가 아닌 memory에 데이터를 저장한다.
- 이때 jemalloc를 사용하는데 굉장히 최적화 되어있어 파편화를 최소화 시킨다.
- non blokcing I/O, Multiplexing
- 간단한 문자나 정수의 경우 encoding을 하여 최적화를 한다.
- 자주 접근되는 데이터는 client cache를 제공하여 네트워크 비용을 최소화 한다.
- redis에서 제공하는 자료구조는 (list, set...) cpu의 L1, L2 캐시에도 최적화 되어 있어 cache miss를 최소화 한다.
이외에도 다른 요인들도 많다. 하나 하나 내용들을 좀 더 자세히 보고싶지만 글이 너무 길어질 것 같고 다른 공부할게 많기에 언젠가 기회가 된다면 다른 글로 정리해볼 예정이다.
결론
이렇게 간단히 redis가 내부에서 어떤식으로 작동하고 어떤 기능들을 통해 성능을 최적화 하는지 알아보았다.
다음 글에서는 redis가 disk에 값을 저장할 때는 어떤 기능들을 지원하는지 정리할 예정이다.
'ComputerScience > DataBase' 카테고리의 다른 글
| 트랜잭션 1편 : 간단 복습하기 (feat: DB는 커밋했는데 커밋 메세지가 유실된다면?) (0) | 2025.05.14 |
|---|---|
| Redis Persistence 알아보기 (RDB, AOF) (0) | 2024.08.24 |
| MySQL GroupBy 사실과 오해 (feat: only_full_group_by, window function) (0) | 2024.05.01 |
| MongoDB 정규화, 반정규화 (0) | 2024.04.28 |
| MongoDB Bulk Ops (feat: insertMany, Bulk Write) 알아보기 (0) | 2024.04.21 |

