
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 2025 계획
- OS
- Spring
- 소프티어
- Service 계층 테스트
- backend
- 테크쇼
- Junit 5
- 일상
- Test
- Java
- modelmapper
- enumSet
- 자바
- mapstruct
- 공룡책
- 2024회고
- softeer
- 직장인 회고
- JPA
- MySQL
- Test Doulbe
- Coputer Science
- FCM
- parallelconsumer
- 인프콘2023
- Server
- proxyFactory
- Test code
- db
- Today
- Total
공부내용공유
node 개발 팁 (feat: event loop, module cache, call by sharing) 본문
서론
사내 프로젝트중 node(type script)로 구현되어져 있는 프로젝트들이 몇 개 있는데 그 중 하나를 업무로 맡게되었다.
지금까지 자바만 사용을 했었고 express와 sequalizer라는 프레임 워크를 사용하여 프로젝트의 구조도 익숙치 않아 조금 낯설었으나 GPT 한테 열심히 물어보고 검색해가면서 열심히 업무를 진행하고 있다.
마침 최근에 공부했던 함수형 프로그래밍의 개념을 좀 더 살려서 개발을 하고 싶기도 하고 node 자체에 대한 이해도가 부족한것 같아 node의 기본적인 메커니즘을 공부하고 정리하고자 이 글을 작성하였다.
본론
이 글의 목차는
- node의 event loop
- module cache
- call by sharing
로 구성될 예정이다.
node의 event loop
예전에 js를 찍먹했을 때 지식과 최근에 친구한테 간단한 설명을 들은 바로는 "node는 event loop이 있고 이를 이용하여 blocking job을 처리한다" 라고 알고있는데 정확히 어떤 메커니즘으로 동작하는지 이번 기회에 정리하였다.

사진 출처인 블로그에 너무 깔끔한 구조 사진과 설명이 나와있고, 이 블로그에도 상세한 코드와 설명이 나와있으니 좀 더 깊이 공부하고자 하는 사람은 참고하면 좋을 것 같다!
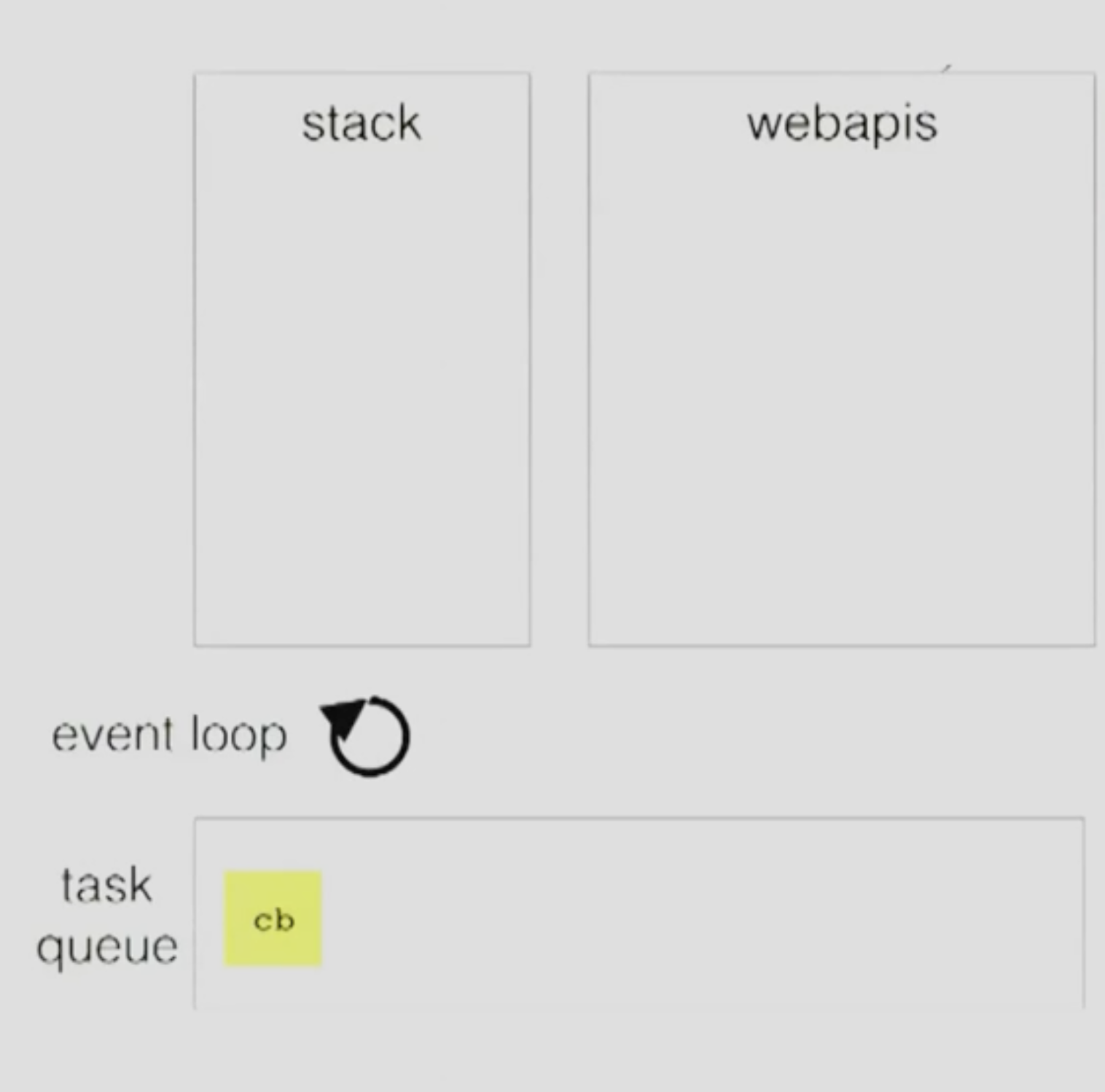
실행과정을 간단히 설명하자면
- 이벤트 루프가 js로 작성된 메인 코드(비즈니스 로직)을 수행한다.
- 수행해야 하는 작업들을 stack 쌓으면서 처리해간다.
- 비지니스 코드를 실행중 blocking job을 만나면 해당 job을 워커 쓰레드 혹은 커널에 위임한다.
- webapi는(커널, 워커 스레드)는 blocking job을 다 처리하면 콜백 함수를 task queue에 넣는다.
- 메인 코드(non-blocking job)을 다 처리하여 stack이 비어있고 task queue에 처리할 job이 있다면 해당 job을 처리한다.
이런식으로 동작한다.
즉 헷갈릴 만한 사항을 정리하자면
- 메인 코드(non-blocking)와 blocking job을 수행하는 코드는 별개의 스레드가 아닌 하나의 메인 스레드가 수행한다.
- disk, network i/o를 처리하기 위한 thread pool이 있다.
- queue는 정확히는 1개는 아니고 여러개의 queue가 있다.
엥? 3번은 무슨 소릴까?
위 사진에도 나와있고 블로그를 봤다면 잘 알겠지만 task queue는 그냥 추상적으로 표현한거고 정확히는 이벤트 루프는
- timer
- pending callback
- idle, prepare
- poll
- check
- close callback
로 구성되어져있고 각각의 단계별로 큐가있어 순서대로 해당 큐에 있는 task들을 처리한다.
이때 만약 task queue에 계속 task가 쌓인다면? 다음 단계로 못갈까? 갈 수 있다. 한 단계에서 너무 오래 막혀있으면 다음 단계로 넘어간다 한다. (못넘어가게도 처리가 가능하다고 한다.)
이 이상으로 깊이 다루고 싶다면 위에 블로그나 검색을 하면 상세히 다룬 글들이 많으니 해당 글들을 참고하자!
module cache
리뷰를 받을 때 node의 모듈은 생성되고 싱글톤 처럼 작동한다는 얘기를 들었다. 읭 그렇습니까? 하고 찾아봤는데 정확히는 node가module을 캐싱하고 해당 모듈을 요청할 때 캐싱된 값을 내어주기에 일종의 싱글톤처럼 작동하는 것이다.
해당 내용은 이 영상에서 굉장히 잘 설명해준다.
예시 코드는 귀찮으니까 js로 작성하겠다. 업무는 type safety를 열심히 신경쓰면서 type script를 사용중이다. ^^
class Troll {
construtor(name) {
this.name = name;
}
getName() {
return this.name;
}
setName(name) {
return this.name;
}
}
module.exports = new Troll("PgAdmin")const troll = require(./Troll);
troll.setName("오또카지");
const troll2 = require("./Troll");
console.log(troll2.getName());
console.log("PgAdmin == 오또카지")
뭐가 나올까? module.exports에서 new 키워드를 사용했으니 당연히 PgAdmin이 나와야 생각할 수 있지만 결과는 오또카지가 나온다. 캐싱이 되었기 때문이다.
import / export의 경우에도 마찬가지로 caching이 적용된다고 한다. 그러니 module를 만들어 사용할 때 statless인지 혹시 stateful 하다면 side effect를 잘 고려해서 사용해야한다.
call by sharing
call by value
let var1 = 1;
function add(var2) { //callee
var2 = var2 + 1;
}
add(var1); //caller
console.log(var1); // 1크게 설명할 것 없는 문법이다. 메서드에 인자로 넘어온 값 자체가 변수에 복사된거기 때문에 기존 변수가 담고있던 값에는 아무 영향을 미치지 않는다.
call by reference
const ceo = {
name : "박성훈";
}
function changeName(person) {
person.name = "신찬규";
}
console.log(ceo); // 박성훈
changeName(ceo);
console.log(ceo); // 신찬규
//신찬규 == 박성훈;
객체의 참조값을 넘기기에 메서드 내부에서 값을 바꾸면 외부에서도 객체의 값이 바뀌어 있다. 이도 익숙한 개념일 것이다.
call by sharing
const ceo = {
name : "박성훈";
}
function changeName(person) {
person = {name : "신찬규"};
}
console.log(ceo); // 박성훈
changeName(ceo);
console.log(ceo); // 박성훈
엥 왜 안바뀌었을까?
call by sharing의 경우 주소의 저렇게 메서드 인수값으로 들어가서 값을 전달할 때 call by referecne와 같이 객체의 주소값을 복사하여 전달한다.
다만 위 코드에서처럼 새롭게 값을 할당하면 새로운 객체가 생성되고 그 객체의 주소 값이 person에게 배정이 된다. 그래서 person과 ceo는 다른 객체를 참조하게되는 것이다. 자바나 파이썬을 사용한 사람이라면 당연한 개념일 수 있지만 한번 정리하면 좋을 것 같아 내용에 넣었다.
결론
다른 더 중요한 내용도 많겠지만 차차 정리하기로 하고 일단 이번 글에서는 이정도로 마무리를 하였다. 최근 공부한 함수형 프로그래밍의 이점을 적극 도입하면서 객체지향과 함수형 프로그래밍의 장점을 잘 살린 코드를 작성해보고싶다!